TL;DR: Given a pair of key frames as input, our method generates a continuous intermediate video with coherent motion by adapting a a pretrained image-to-video diffusion model.
Abstract
We present a method for generating video sequences with coherent motion between a pair of input key frames. We adapt a pretrained large-scale image-to-video diffusion model (originally trained to generate videos moving forward in time from a single input image) for key frame interpolation, i.e., to produce a video in between two input frames. We accomplish this adaptation through a lightweight fine-tuning technique that produces a version of the model that instead predicts videos moving backwards in time from a single input image. This model (along with the original forward-moving model) is subsequently used in a dual-directional diffusion sampling process that combines the overlapping model estimates starting from each of the two keyframes. Our experiments shows that our method outperforms both existing diffusion-based methods and traditional frame interpolation techniques.
Method
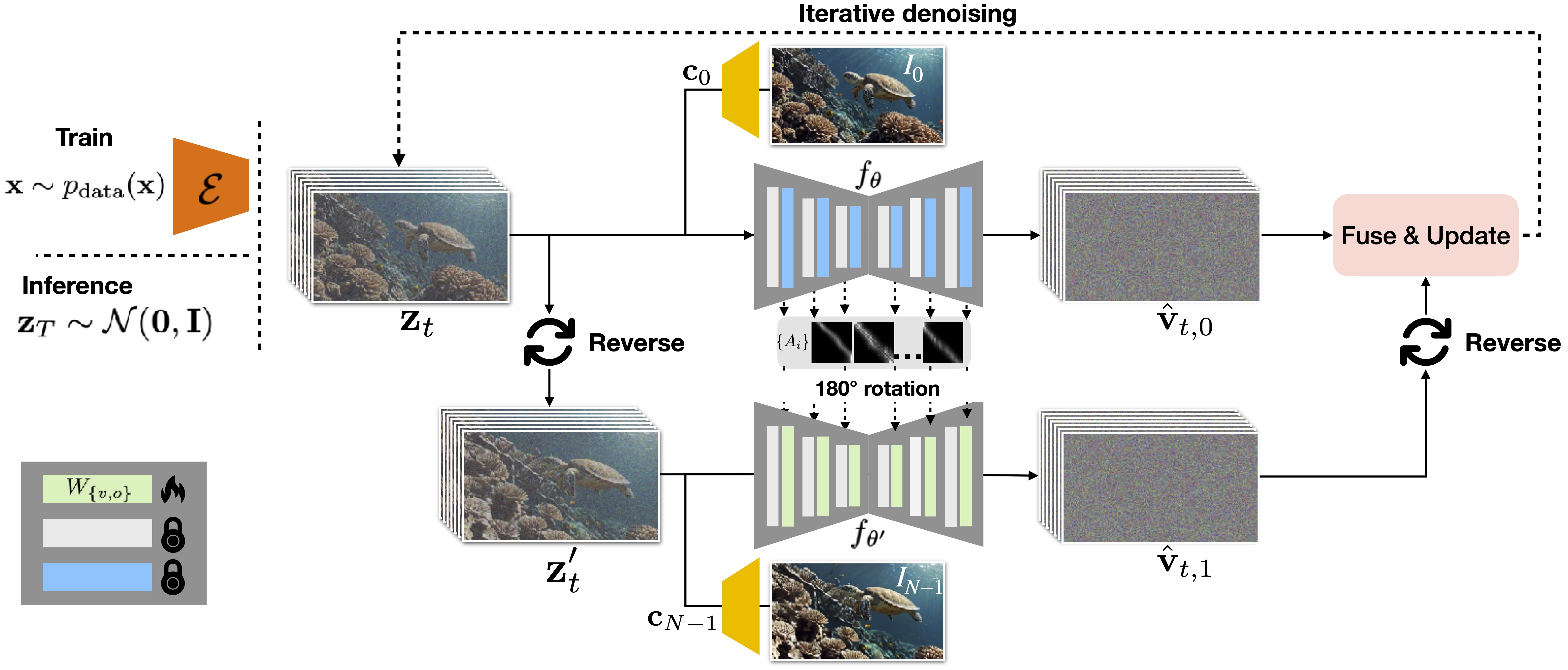
The pipeline includes three stages: (1) Forward motion prediction: we first take the conditioning of the first input image (inference stage) or the first frame in the video (fine-tuning stage), along with the noisy latent to feed into the pre-trained 3D UNet to get the noise predictions, as well as the temporal self attention maps. (2) Backward motion prediction: We reverse the noisy latent along temporal axis, and then we take the conditioning of the second input image, or the last frame in the video, along with the 180-degree rotated temporal self-attention maps, and feed them through the fine-tuned 3D UNet for backward motion prediction. (3) Fuse and update : The predicted backward motion noise is reversed again to fuse with the forward motion noise to create consistent motion path. Note that only the value and output projection matrices in the temporal self-attention layers (green) are fine-tuned.
Baseline comparisons
Input pairs
FILM
TRF
Ours
Input pairs
FILM
TRF
Ours
Input pairs
FILM
TRF
Ours
Input pairs
FILM
TRF
Ours
Input pairs
FILM
TRF
Ours
Input pairs
FILM
TRF
Ours
Input pairs
FILM
TRF
Ours
Input pairs
FILM
TRF
Ours
Input pairs
FILM
TRF
Ours
Input pairs
FILM
TRF
Ours
Input pairs
FILM
TRF
Ours
Baseline comparisons in articulated motions
Input pairs
FILM
TRF
Ours
Input pairs
FILM
TRF
Ours
Input pairs
FILM
TRF
Ours
Ablation Study
Input pairs
Ours w/o RA
Ours w/o FT
Ours
Input pairs
Ours w/o RA
Ours w/o FT
Ours
Input pairs
Ours w/o RA
Ours w/o FT
Ours
Keyframe interpolation with variable second frames
Input frame 1
Our results
Input frame 2
Input frame 1
Our results
Input frame 2
Input frame 1
Our results
Input frame 2
Acknowledgements
We would like to thank Meng-Li Shih and Dor Verbin for helpful discussions, feedback, and manuscript proofreading. We also would like to thank Zihao Ye for computational resources support.
BibTeX
@article{wang2024generative,
title={Generative inbetweening: Adapting image-to-video models for keyframe interpolation},
author={Wang, Xiaojuan and Zhou, Boyang and Curless, Brian and Kemelmacher-Shlizerman, Ira and Holynski, Aleksander and Seitz, Steven M},
journal={arXiv preprint arXiv:2408.15239},
year={2024}
}